AWS Startups Blog
How ipdata uses AWS to serve a global, highly-scalable IP geolocation API
Guest post by Jonathan Kosgei, Founder of ipdata

Uber redirects visitors to translated pages based on their location
You’ve probably encountered websites like Uber that customize their content based on your location.
Whether it’s auto-filling forms with your country name so that you don’t have to, or determining what currency to show you prices in, or showing you the time in a colleague’s timezone, modern websites have grown very savvy about customizing their content based on your location.
There is an endless number of possible applications for the data the ipdata.co API provides. Some that we did not envision ourselves. The teams at Cooperpress and Quay.io, for example, use our threat data to prevent spam signups and as an addition or alternative to CAPTCHAs.
Ipdata can provide website owners with an extraordinary amount of information from an IP address.
In this post, we’ll cover how we’ve built a highly scalable API with low latency globally on AWS API Gateway. We’ll cover how we’ve handled Authorization, Rate Limiting, High Availability, and DDoS protection.
How We Started Out
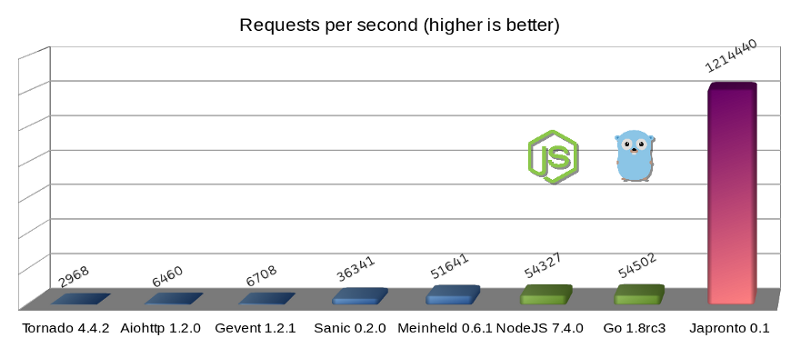
When we first launched in October 2017, we ran on a couple of EC2 instances in three AWS regions using the Japronto Python Framework. A few months in, we found ourselves looking for an economical way to increase the number of regions where we were present.
Quite conveniently a week before Re:invent 2017, AWS announced regional endpoints for API Gateway, which would turn out to be the pillars of our new infrastructure.
Overview

A simplified depiction of our infrastructure by Adrian Hornsby of acloud.guru.
Instead of one edge-optimized API Gateway API we have 11 regional endpoints. 11 AWS Regions use Route 53’s latency-based routing to route requests to the endpoint closest to the user. We’ve weighed both options and we chose not to go with an edge optimized API Gateway setup because despite users’ requests getting off the public internet and onto Amazon’s network sooner thanks to the use of CloudFront endpoints, the point of execution was still the region in which the API was created. So if the edge-optimized API was created in N. Virginia and a user from Australia made an API call, they’d have to wait for their request to be sent to N. Virginia and for the response to be computed and sent back.
Instead with our current setup, Route 53 would send the user’s request to our Sydney endpoint and the user would have their API call processed and returned in the same city as them. We’re able to cover the major cities where AWS has regions. However, just processing requests on the same continent as the user can reduce latency for them by more than twofold.
Lambda
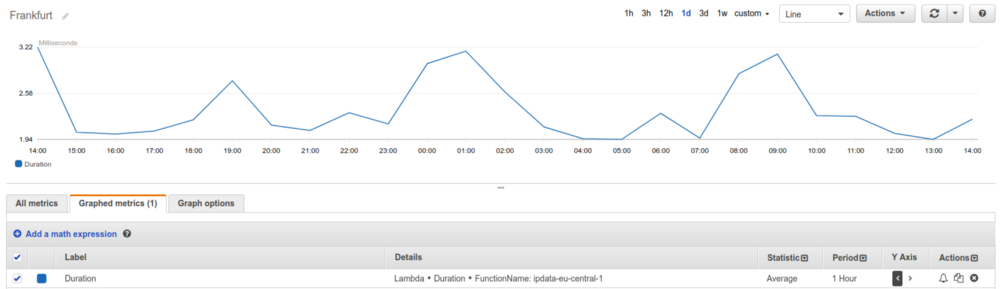
ipdata is written in Python 3 with an average execution time of 2.9ms.
We’re able to keep our execution time low by not doing any database reads or writes in the application code. A separate authorizer function handles getting usage data from DynamoDB and authorizing users based on whether they’re within their quota or not. And its results are cached.
Authorization
One of the best things we did that we should’ve done sooner, was use API Gateway Lambda Authorizers. We get anywhere from 100–200M unauthenticated requests a day that we turn away with lambda authorizers. API Gateway doesn’t charge for 4XX responses. And what we’ve done is customize our Gateway responses to make the accompanying message relevant to the error.

Sample 403 Error message for when you exceed your quota or fail to provide an API key.
The response codes from custom authorizers are still limited. You can only return 200s, 401s and 403s with only 200s and 403s being cached. Also, the messages are static. They are not customizable from within the authorizer code. So you can’t personalize error messages and include stats. For example, telling users when their quota will reset. We do this via email, however, when the user is at 90% of their plan quota.
We’ve found it very convenient to have all the Authorization logic separate from our application code and it’s made us a lot more comfortable making changes. All the authorizer needs to do is return a 200 for legitimate users with sufficient quota remaining or return a 403 in any other case.
Rate Limiting
With 11 endpoints all over the world, our biggest challenge was how to synchronize usage data across all our endpoints. Take this, for example: a user in London makes 10M calls to our API. Route 53 routes their requests to our London endpoint where their usage is recorded (more detail on this later). What’s to stop the user from spinning up a server in the US or using a proxy to continue making requests and hitting our other endpoints that have no record of their London usage?

To solve this we use a combination of CloudWatch Log Subscription Filters, Kinesis Data Streams, and a single server running a number of Kinesis consumers and Redis.
We record usage data by printing a log with all the user identifiers, the API Key and IP Address in the API Lambda function and send that to Kinesis via a CloudWatch subscription filter.
Simply;
print(event)
All the log events are sent to Kinesis and consumed by multiple workers. The workers maintain a count in Redis of how many requests an API key, IP Address or Referer has made. We then have another program constantly read from Redis and run Batch Writes containing usage data to our DynamoDB tables in each region.

We use RQ Workers to process Kinesis Records.
This system has worked very well for us. Our single server has been able to keep up with hundreds of millions of calls a day very reliably.
Kinesis has also been very reliable and very fast. Log events from endpoints in Sydney to Sao Paulo to London are received and processed in a fraction of a second.
Note that we made several Redis optimizations, like using pipelines and mget to improve our throughput. Before, reading the usage data for about 350,000 IP addresses would take up to 2 minutes but with these optimizations, it now takes between 8 and 10 seconds.
User Management
In June, at the height of a DoS attack, we found that the only way to end it and insulate ourselves from anything like it in the future was to require users to have API keys. This would give us the usage granularity we needed, and make it easy for us to spot and stop malicious users.
We couldn’t use API Gateway’s Usage plans and API keys, because there’s currently no way to sync usage data between multiple API Gateway APIs. We therefore had to develop our own means of creating and distributing API keys. Which turned out to be easy to do as you can make database calls and implement your own auth logic however you like with Custom Authorizers.
We were able to implement a secure log in system within a day thanks to Amazon Cognito.
To create user accounts for free users we used Cognito with a Lambda Trigger on email confirmation.
Users signup on our website here, Cognito then sends them an email with a confirmation link and once they verify their email, Cognito triggers a lambda function that generates an API key and emails it to them via SES.
The integration was smooth and easy. And we now have the foundation in place to develop more user management features. We could enable MFA or Remembering Devices with little effort. All mundane account actions such as remembering the user, resetting forgotten passwords, logging in and more are easily implementable in a few lines of Javascript.
Abuse

I’ve hinted a lot about how a month-long DDoS attack forced us to refactor our handling of Authentication and Rate limiting. From Friday 11th May through to July, malicious users sent us 1B+ (a few thousand dollars in traffic) API calls in a HTTP GET Flood.
The calls were indistinguishable from legitimate usage— as we did not yet require API keys on the free tier. The first thing we had to do was refactor our Kinesis worker which at the time used Local Dynamodb and used the Cross Region Replication Library to sync usage across all 11 regions. As mentioned before we tried moving it to Lambda but it didn’t process records fast enough, despite several hacks. Hence the move to Redis.
We realized a huge amount of the traffic was coming from Russia, Kazhakstan, Oman, Pakistan, New Caledonia, Libya and a number of other countries. So the first big step we took was blocking countries.
We used the IP country blocks lists from IPdeny to get a list of all networks from all the worst offending countries and put them in our API Gateway Resource Policies to be blocked explicitly. This gave us some reprieve, but our daily costs were still 5X times our usual.
Next, after going through some of the offending ip addresses and networks, we found that a large percentage of them were listed in a number of popular DNSBLs. We therefore incorporated DNSBL checks in the authorizer code and that helped a bit.
However, we still saw a lot of illegitimate traffic going through and finally decided to require API keys on the free tier.
Lessons
- Using sentry in our Lambda functions is one of the best things we have done. We get detailed information on any errors that occur, the number of users affected, all runtime variables, the function name, AWS region, and more.
- At a certain scale, the fixed costs of actual servers is tempting. However, never having to worry that you’ll wake up in the morning and find your service was down the whole night because of an unexpected server reboot is one of the huge pluses of being serverless.
- CloudWatch dashboards are very useful. They’re $3 each and the first three are free.
- Not everything has to be serverless. Use servers where it makes sense to use them, i.e. for long running jobs.
- During the DDoS we interacted with various support teams at AWS almost every single day and looking back I can say it was all a positive experience. Everyone I talked to was very helpful and proactive in helping us resolve our issues.
Conclusion
I’ve learned a lot building ipdata over the past year and I’m happy with how things turned out. We’ve built the fastest IP Geolocation API out there running out of 11 AWS regions and are used by NASA, AMD, Ring, Redhat, Accenture, McKinsey, Stanford, and hundreds of other organizations.
See this comparison of the most popular IP Geolocation APIs to see how we fare.